DeformableDETR论文阅读梳理
本文最后更新于 2024-08-17,文章内容可能已经过时。
DCN(Deformable Convolution Networks): 在卷积当中引入了学习空间集合形变的能力,不再是使用常规的领域矩阵卷积,而是让卷积自动的去学习需要卷积的周围像素,以此可以适应更复杂的几何形变任务。
作者想法:将DCN和DETR相结合,DETR不是收敛慢和计算量大麻,而且主要的原因是transformer模块带来的频繁计算(每个位置需要计算和其他所有位置的相似度,而不是像卷积那样共享参数),那么很朴素的想法就是: 让每个位置不必和所有的位置交互计算,只需要和部分(学习来的,重要的部分)进行交互即可。
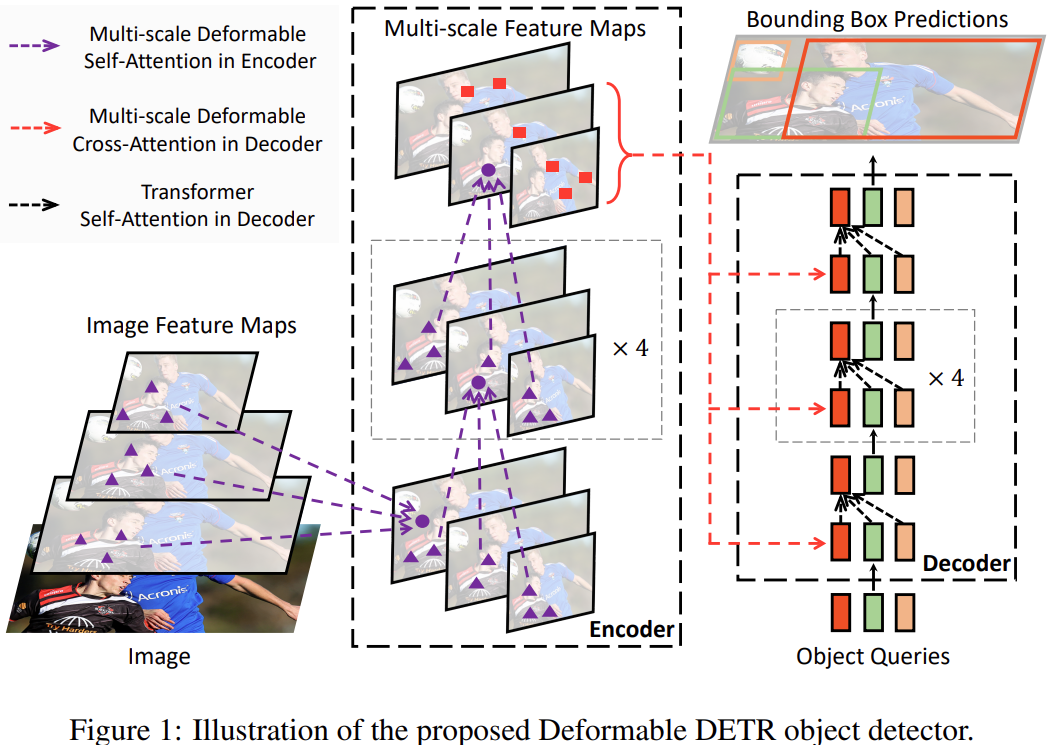
可变形多头注意力(DeformAttn)
可变注意力: 通俗的讲就是query不是和全局每个位置的所有key都计算注意力权重,而是对每个query,仅在全局位置中采样 局部/部分 位置的key(自学习的方式),并且value也是局部位置的value,最后把这个 局部/稀疏 的注意力权重和局部value进行计算。
原始的transoformer Attention的多头注意力公式如下:
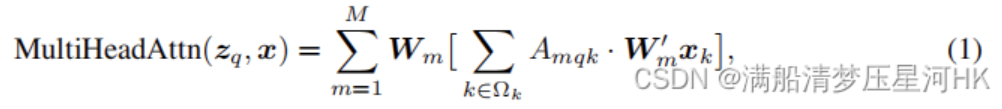
其中,x是输入特征, z_q表示query,由x经过W_q线性变换来的,k是key的索引,q是query的索引,M表示多头注意力的头数,m代表第几注意力头部,A_{mqk}表示第m头注意力权重, W_{m}^’x_k其实就是value,整个[]内的过程就是全过程,W_m是注意力施加在value之后的结果经过线性变化从而得到不同头部的输出结果,\varOmega_k表示所有key的集合。
可变形多头注意力公式:
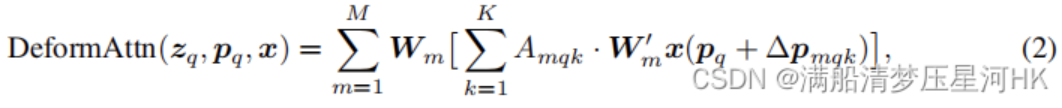
可以发现公式2和公式1很相似,有两点区别:
采样局部的key,即k的范围缩小了。原始的k是所有的key的集合,而这里的k只采样K个位置。具体点说: 每个头: 每个query只在key中采样K个位置,计算他们的注意力,即A_{mqk}
value也是采样局部的value(基于采样点插值出来的value)。即公式2中的W_m^’x(p_q+\varDelta p_{mqk}),主要是p_q 和\varDelta p_{mqk} 起的作用,其中p_q 表示代表query的位置z_q,可以理解为2d向量/坐标,作者称为参考点(reference points, 定量), \varDelta p_{mqk} 是采样点相对于参考点的位置偏移(offsets,可学习的).
多尺度可变形多头注意力: MSDeformAttn
多尺度可变形多头注意力公式:
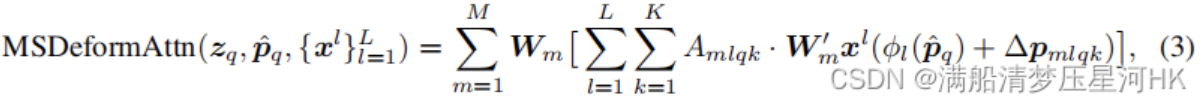
式3和式2也很像,区别:
多尺度,即L代表总共有L层特征,l代表第l层特征
\hat{p_q}代表归一化的参考点坐标,\text{\o}_l表示将归一化后特征坐标映射到第l层特征上去,所以\text{\o}_l(\hat{p_q}) 之后,每个参考点在第l层上都会有一个对应归一化后的坐标,从而方便我们计算出不同特征层哪些采样点的位置。
问题思考
1.为什么MSDeformAttn中的attention weight不是transformer里面那样key来与query交互计算,而是由query经过全连接层得到的?
答:我们知道,在Transformer中,注意力权重是由query和key交互计算得到的。然而,在这里却像开挂般直接通过query经全连接层输出得到,为什么呢?要回答这个问题,就要先看看Deformable DETR的参考点(Reference Points)和query之间的关系。
Encoder: 参考点是特征点本身的位置坐标(特征坐标的中心,如0.5, 0.5), query = 特征 + scale_level position embedding;
Decoder: 1阶段时,query_obj和query pos都来自预设的query_embed, 参考点由query posJingguo1
